
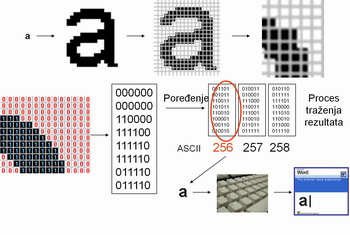
 Osnovni zadatak OCR softvera je da vaše digitalne slike, na kojima se nalaze skenirani tekstovi sa matričnih štampača, kucaćih mašina, knjiga, novina, časopisa ili poslovne dokumentacije, pretvori u promenljive digitalne tekstualne forme, tako što će iz rastera tačaka, sa slika, prepoznati slova, reči i čitave tekstove.
Osnovni zadatak OCR softvera je da vaše digitalne slike, na kojima se nalaze skenirani tekstovi sa matričnih štampača, kucaćih mašina, knjiga, novina, časopisa ili poslovne dokumentacije, pretvori u promenljive digitalne tekstualne forme, tako što će iz rastera tačaka, sa slika, prepoznati slova, reči i čitave tekstove.
Verovali ili ne, prvi rad na OCR tehnologiji imao je Austrijanac Gustav Tauschek davne 1929. godine i taj pronalazak je iste te godine patentiran u Nemačkoj. Ova tehnologija će u savremenom informatičkom svetu napraviti veliku revoluciju na polju automatizacije mnogih aktivnosti u vezi sa papirnom dokumentacijom i odvešće nas u jedan sasvim novi svet analitike i istraživanja.
Sa posebnim zadovoljstvom predstavljamo Vam servis za pretragu novinskih izdanja, knjiga i časopisa po unutrašnjem sadržaju. Ozbiljan posao je urađen pod okriljem Univerzitetske Biblioteke Svetozar Marković iz Beograda gde je tim vrednih ljudi na platformi softvera docWorks omogućio posetiocima internet sajta Univerzitetske biblioteke da mogu pretraživati digitalizovane istorijske novine i druge sadržaje po unutrašnjem sadržaju teksta. Pored softvera docWorks, u osnovi ovog softvera funkcioniše OCR program Ruske kompanije ABBYY FineReader. Navodimo Vam još jedan ključan detalj sa sajta Univerzitetske biblioteke koji pomaže da čitav sistem radi u internet okruženju:
Sadržaj koji je digitalizovala Univerzitetska biblioteka „Svetozar Marković“ iz Beogradu u okviru projekta Europiana novine (Europiana Newspapers) i koja se nalazi u kolekciji Istorijskih novina prikazuje se pomoću softvera koji se delimično zasniva na otvorenom softveru bnlviewer koji je razvila Nacionalna biblioteka Luksemburga.
Osvrtom na aktuelnu ponudu OCR softvera primećujemo nekoliko osnovnih pravaca kojima se kreću razvojni timovi koristeći ove tehnologije. Za rešenja koja su okrenuta poslovnom svetu, cilj je svima isti, dematerijalizacija papirnih dokumenata, a u tom poslu pomažu nam sledeće discipline:
- Velika brzina prilikom masovne digitalizacije
- Automatizovana separacija dokumenata, auto sortiranje, strukturiranje dokumenata i sadržaja
- Optical Character Recognition, Inteligent Document Recognition, indexiranje
- Kompresija dokumenata i digitalnih slika
Najveći izazovi su svakako organizacije masovnog procesuiranja dokumentacije OCR rešenjima. Za ovakve poslove neophodno je prepoznati osnovne principe organizacije sistema i njegove arhitekture. Navešćemo samo nekoliko ključnih procesa. Bez sumnje prvi korak je uvoz podataka u sam sistem digitalizacijom dokumentacije ili importo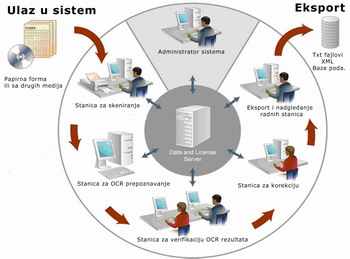 m digitalnih fajlova u sam sistem. Analizom dokumentacije koja se propušta kroz proces prepoznavanja otvoriće nam se niz mogućnosti za podešavanje sistema, od jezika kojim je tekst pisan do definisanja tabela i različitih formi informacija na koje će nailaziti softver za prepoznavanje. Što se više posvetite definisanju očekivanih informacija na podlogama koje će softver obraditi, to će rezultati očitavanja imati veliki procenat uspešnosti. Ono što je u direktnoj vezi sa preciznim podešavanjem sistema pre samog prepoznavanja je proces validacije i verifikacije uspešnosti onoga što je softver uradio. Ako želite visok stepen u kvalitetu prepoznavanja proces validacije je nezaobilazna stavka. Iako su softveri prilično dobro rešili rad operatera na validaciji, ovo je bez sumnje najsporiji manuelni rad koji bez ljudskog oka i rada ne može da funkcioniše. Nakon definisanja i otklanjanja svih nepravilnosti, rezultate OCR-a eksportujemo ka našim željenim formama i destinacijama.
m digitalnih fajlova u sam sistem. Analizom dokumentacije koja se propušta kroz proces prepoznavanja otvoriće nam se niz mogućnosti za podešavanje sistema, od jezika kojim je tekst pisan do definisanja tabela i različitih formi informacija na koje će nailaziti softver za prepoznavanje. Što se više posvetite definisanju očekivanih informacija na podlogama koje će softver obraditi, to će rezultati očitavanja imati veliki procenat uspešnosti. Ono što je u direktnoj vezi sa preciznim podešavanjem sistema pre samog prepoznavanja je proces validacije i verifikacije uspešnosti onoga što je softver uradio. Ako želite visok stepen u kvalitetu prepoznavanja proces validacije je nezaobilazna stavka. Iako su softveri prilično dobro rešili rad operatera na validaciji, ovo je bez sumnje najsporiji manuelni rad koji bez ljudskog oka i rada ne može da funkcioniše. Nakon definisanja i otklanjanja svih nepravilnosti, rezultate OCR-a eksportujemo ka našim željenim formama i destinacijama.